Tópicos
Existem dois principais modelos baseados em regressões:
- Linear, para problemas de regressão
- Logística, para problemas de classificação
Linear
Tem como objetivo prever o valor de uma variável baseando-se no valor de outra, minimizando, sempre, o erro. Este erro (perda ou função de custo) é calculado segundo a média dos quadrados dos erros (MSE).
Existe uma variação deste algoritmo em que é possível utilizar o valor de várias variáveis para prever uma outra, sendo esta variação a mais comummente utilizada.
Logística
Utiliza modelos de regressão para realizar uma classificação binária.
A este modelo é aplicada uma função sigmoid, que dado qualquer valor ajusta-o ao intervalo [0, -1]. Este resultado é compreendido como a probabildiade desse valor ser dessa dada classe.
Assim, caso tenhamos mais que duas classes, necessitamos de treinar um modelo binário para cada classe separadamente.
Minimização de Erro
Em ambos os modelos apresentados, o objetivo será sempre minimizar o erro final, para que o modelo performe melhor e preveja mais acertadamente.
Esta minimização pode ser feita de várias formas:
- MSE
- Gradient Descent (pode não convergir ou convergir muito lentamente, se mal configurado)
Fatores para que o gradient descent não convirja ou convirja lentamente
- Existência de pontos de sela, onde o gradiente é 0, mas não é um mínimo
- Má configuração de inicialização
- Mau valor para o learning rate
- Muito alto: diverge
- Muito baixo: ou não converge ou converge muito lentamente
Cuidados a ter
Especialmente na regressão logística, é comum acontecer overfitting.
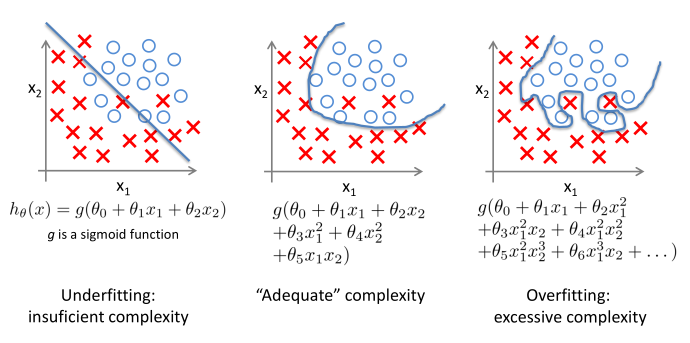
Como forma de atenuar este problema, podemos reduzir o número de features usadas (coeficientes).