Tópicos
Porquê Benchmarking?
Benchmarking é útil pois permite-nos testar as implementações produzidas, ao nível da eficiência e robustez, por exemplo.
Como é que podemos saber que o sistema está a usar os recursos físicos e lógicos de forma eficiente? Usamos benchmark.
Como é que podemos saber que o ambiente onde o sistema está a rodar possui recursos suficiente? Usamos benchmark.
Ecossistema
Um ecossistema de benchmarking é composto por três componentes.
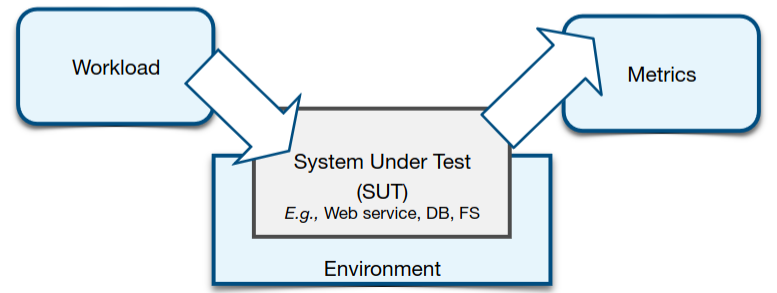
Workload
Consiste no grupo de pedidos que estão a ser colocados ao SUT (System under Test).
Existem dois tipos de workloads que podem ser utilizados.
Traces de pedidos
- Possui a vantagem de estarmos a extrair informação de workloads reais (feitos por utilizadores reais em produção)
- Possui a desvantagem de ser difícil de obter e escalar. Como é que se escala um trace com 100 pedidos para um trace com 1 milhão de pedidos sem perder realismo?
Workloads sintéticos
- Utiliza um subset de pedidos gerados sinteticamente. Por exemplo, um conjunto de queries feitas à base de dados; um conjunto de operações feitas ao sistema de ficheiros, etc.
- Possui a vantagem de podermos simular diversos comportamentos (ao nível do tipo de pedido, tamanho, etc). No entanto, perdemos a questão do realismo.
Ambiente
Ambiente onde o SUT está a correr.
É importante que o ambiente onde se está a testar o SUT seja facilmente reprodutível, para que outras pessoas possam chegar aos “mesmos” resultados.
Deve ser, ainda, possível caracterizar o ambiente inequivocamente. Qual o hardware e software utilizados.
Métricas
As métricas colecionadas e calculadas para medir fatores como a performance, eficiência e/ou robustez do SUT.
Tempo de resposta (RT) O intervalo de tempo entre o pedido do utilizador e a resposta do sistema. Também referido como latência ou RTT no contexto de redes de computadores.
À medida que a carga no sistema aumenta, espera-se que este métrica piore, ou seja, aumente.
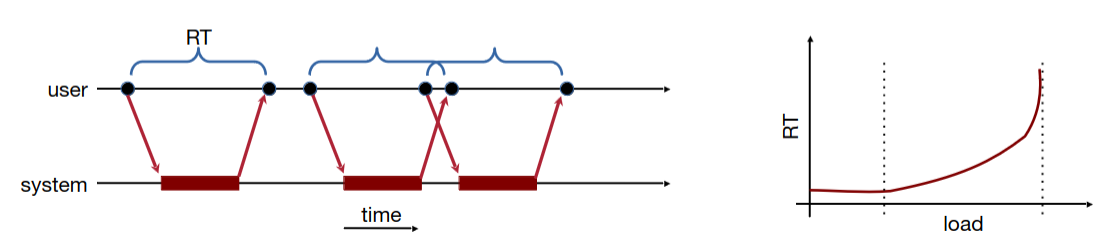
Débito Rate ao qual os pedidos dos utilizadores são servidos pelo sistema (operações feitas por unidade de tempo).
À medida que a carga no sistema aumenta, espera-se que esta métrica piore, ou seja, diminua.

Apesar destas métricas parecerem inversas uma da outra (), nem sempre isto é verdade. Isto é apenas verdade quando o sistema está 100% ocupado e a executar apenas 1 pedido de cada vez.
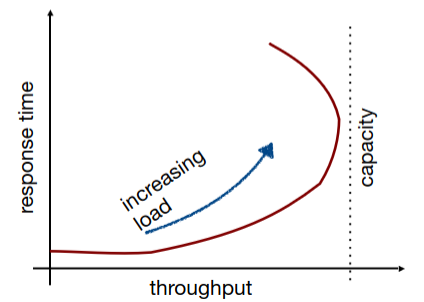
A partir deste gráfico é possível depreender que à medida que a carga imposta no sistema aumenta, o débito e o tempo de resposta aumentam. Isto até o ponto em que o sistema atinge a sua capacidade nominal, onde o débito começa a diminuir e o tempo de resposta continua a aumentar.
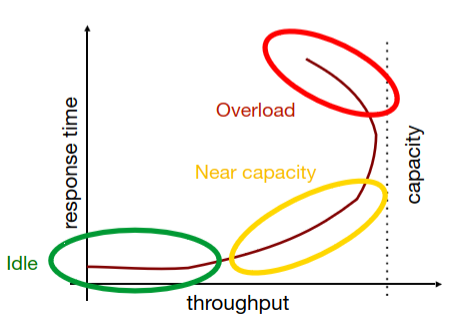
Basicamente, existem três fases:
Idle
- Os pedidos são imediatamente atendidos, já que o sistema continua com capacidade.
Near capacity
- Os pedidos são atendidos depois de algum tempo (métricas a aumentar).
Overload
- Os recursos ficam saturados (débito diminui e tempo de resposta aumenta).
Podem ser consideradas outras métricas para além das descritas, tais como:
- Utilização dos recursos (CPU, RAM, Disco, etc)
- Eficiência energética do sistema
- Robustez do sistema (número de erros ou tolerância a falhas)
- Disponibilidade do sistema (uptime)
Análise de Métricas
É aconselhado que sejam recolhidas métricas sobre várias samples de pedidos diferentes. Isto pois, não só é possível realizar um tratamento de outliers, como temos acesso a uma maior diversidade de resultados.
Depois de colecionadas, as métricas, podem ser analisadas e sumarizadas segundo algumas técnicas matemáticas: média, desvio padrão, moda, mediana, percentis, etc.
A representação das métricas recolhidas também deve ser expressa em gráficos: ao longo do tempo e no que toca à frequência (a frequência mais alta é a moda).
Frequência
Dispor as métricas recolhidas consoante a sua frequência, permite-nos uma melhor análise de alguns fatores.
Por exemplo, se usarmos uma função cumulativa de frequência, podemos facilmente observar a média, percentis, quartis, etc. Muito útil para responder a requisitos impostos pelo cliente: “80% dos pedidos devem ser servidos em menos de 150 ms”.
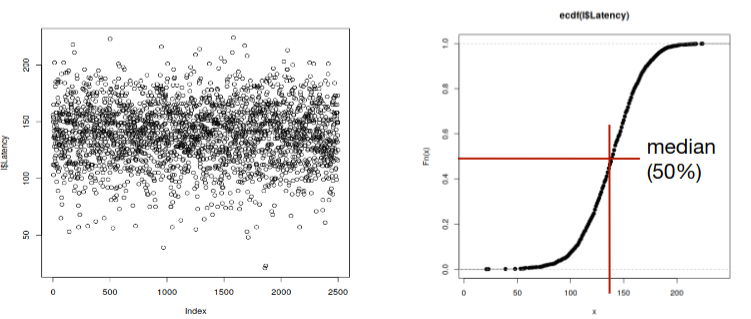
É, ainda, possível analisar outros fatores impactantes do SUT.
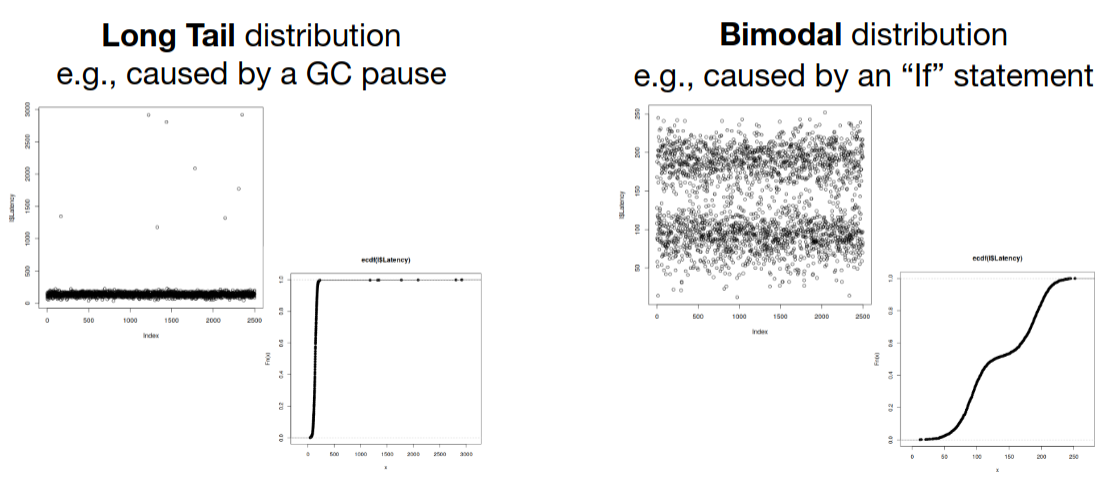
Problemas Comuns
Durante a realização de benchmarking, é comum que os seguintes problemas sejam cometidos.
- Absência de um objetivo
- Não ser possível reproduzir os testes realizados, por falta de documentação ao nível dos workloads, ambiente e configurações
- Workloads serem pouco realistas e representativos
- Análise dos resultados fraca (pouca) e errada (mal interpretada)