Tópicos
Técnica de machine learning baseada no funcionamento do cérebro humano. Este tipo de modelos memorizam casos de treino e não padrões de previsão.
Neurões
Recebem um set de inputs, dados e conexões (a quais neurões se ligam). Cada neurão calcula o seu valor de ativação baseando-se nos inputs e nos pesos das conexões. O sinal calculado é, depois, passado para o output após ser filtrado por uma função de ativação.
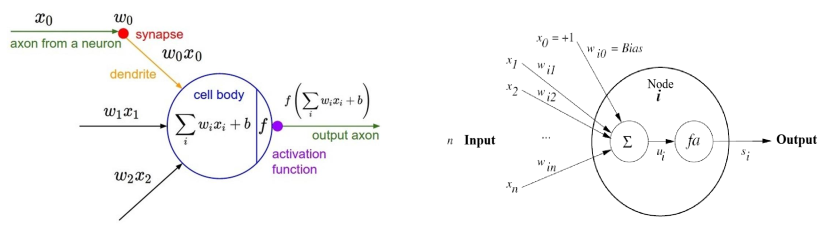
Funções de Ativação
Funções que executam no final de cada camada e em cada neurónio, alterando o input que é cedido à camada seguinte.
Exemplos:
- Sigmoid ou logística
- Linear
- Tangente hiperbólica (tanh)
- Gaussian (normal)
- Relu
Existem ainda funções de ativação que são exclusivamente utilizadas na última camada. É o caso da softmax.
Feedforward
Topologia onde os nós de uma camada estão totalmente conectados aos da camada seguinte. Mais conhecida como Multilayer Perceptron (MLP).
Treino da Rede
O objetivo com o treinamento da rede é fixar os valores dos pesos nas conexões, de modo a minimizar a função de custo.
Existem vários algoritmos de treino, mas abordamos apenas o backpropagation.
Backpropagation
Algoritmo baseado no vetor gradiente, método similar ao gradient descent. Um parâmetro importante, aqui, é o learning rate, que define qual a “distância que se anda”.
O treino executa por um dado número de épocas (epochs) e os exemplos são, tipicamente, divididos em batches.
Existem vários critérios de paragem para o treinamento:
- Número fixo de épocas atingido
- Baseado num nível de convergência definido
Forward propagation Realiza-se uma execução normal da rede e calcula-se o erro cometido ao longo das camadas.
Backpropagation Dado o erro cometido, este é propagado para trás e os pesos das conexões são ajustados de forma a que este seja minimizado.
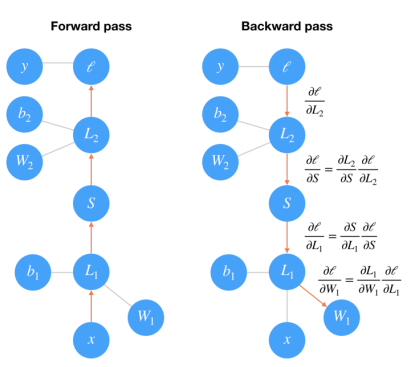
Em suma, uma rede neuronal pode ser definido em termos de:
- Funções de ativação
- Uma topologia de rede (número de nós e camadas)
- Algoritmo de treino
De notar que o número de nós na primeira camada é igual ao número de features existentes nos dados de treino e o número de nós na última camada ao número de outcomes possíveis (número de classes, por exemplo).
Desafios
Durante o treino de redes neuronais é comum o surgimento de alguns problemas.
Underfitting
Pelo facto do modelo ser muito simples ou possuir features insuficientes como input. Isto pode ser reconhecido quando o erro, tanto nos dados de treino como de validação, é muito alto.
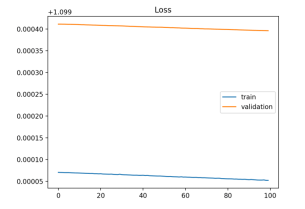 Neste caso, o modelo deu underfit pelo facto de não possuir capacidade para aprender alguma coisa. A solução passa por adicionar mais samples, features ou reduzir a regularização do modelo (dropout layers, etc).
Neste caso, o modelo deu underfit pelo facto de não possuir capacidade para aprender alguma coisa. A solução passa por adicionar mais samples, features ou reduzir a regularização do modelo (dropout layers, etc).
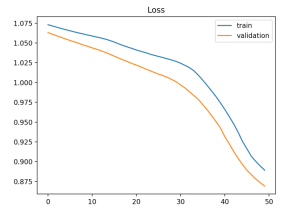 Novamente, estamos perante um caso de underfit. No entanto, desta vez o modelo deu underfit porque precisa de mais treino (a perda ainda não estabilizou). A solução passa por aumentar o número de épocas ou então a learning rate.
Novamente, estamos perante um caso de underfit. No entanto, desta vez o modelo deu underfit porque precisa de mais treino (a perda ainda não estabilizou). A solução passa por aumentar o número de épocas ou então a learning rate.
Overfitting
Modelo demasiado complexo ou treinado durante muito tempo, fazendo com que memorize todos os casos dos dados de treino e generalize pouco.
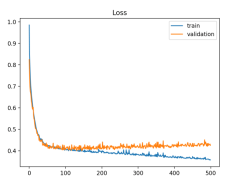
A solução para prevenir o overfit é, na maioria dos casos, ou reduzir a learning rate ou reduzir a complexidade da rede.
Problemas com os dados
Pode acontecer do problema não estar diretamente no modelo e no seu funcionamento, mas sim na forma como os dados representam o problema.
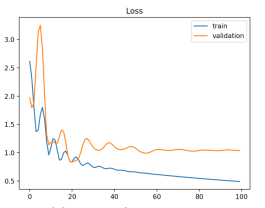
Aqui estamos perante um caso em que os dados de treino são, em relação aos de validação, muito menos. A solução passa, por exemplo, por realizar cross-validation.
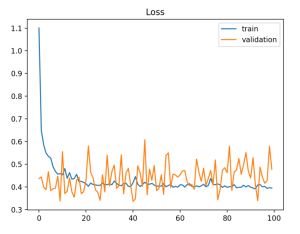
Desta vez, é ao contrário. Os dados de validação são muito menos representantivos que os de treino. A solução passa por adicionar samples aos dados de validação.
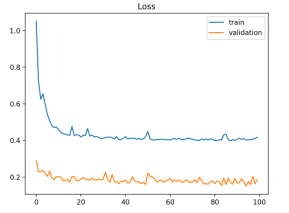
Neste caso, os dados de validação são mais fáceis de prever que os de treino (o erro é menor no de validação). A solução passa por garantir que não existem samples duplicadas nos dois conjuntos de dados e que a divisão está a ser justa.