Tópicos
Conceitos
Deve-se dar grande importância à visualização de dados, muitas vezes negligenciada.
Variáveis independentes Features de input
Variável dependente Target (class ou label)
Preparação de Dados
Básica
JOIN Operação que combina dados de diferentes fontes.
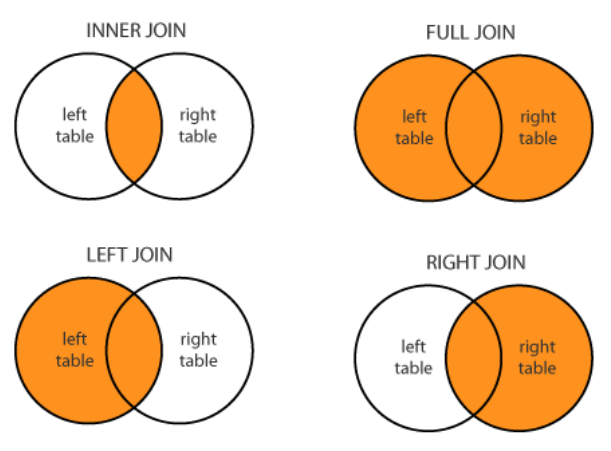
Existem outras técnicas que podem ser usadas, tais como:
- União e interseção de colunas
- Concatenação
- Filtros (por coluna, por linha, consoante o tipo, etc)
- Agregação (contar valores, remover colunas com valores únicos, etc)
Avançada
Feature Scaling O objetivo aqui passa por normalizar a amplitude de valores das features independentes.
Existem dois tipos de scaling que se pode fazer:
- Normalização, onde todos os valores passam a estar entre 0 e 1)
- Standardização, formando uma distribuição normal (gaussiana) onde a média é 0 e o desvio padrão 1 (nem sempre é possível aplicar)
Outlier Detection A deteção de outliers, para consequente processamento, pode ser feita de várias formas:
- Utilizando métodos estatísticos (z-score, box plots, etc)
- Conhecendo o domínio do problema. Por exemplo, remover toda a gente cujo salário mensal seja maior que 1 milhão de euros
- Utilizando modelos de machine learning (SVMs com uma classe, clustering, etc)
O dilema está em se devemos eliminar estes outliers ou ajustá-los aos valores mínimos e máximos.
Feature Selection Este tipo de preparação tem como objetivo selecionar quais features devem ser usadas para criar o modelo.
A remoção de features não importantes pode trazer algumas vantagens:
- Reduzir overfitting do modelo
- Melhorar a accuracy
- Diminuir o tempo de treino, visto que estamos a diminuir a complexidade
Em que situações podemos remover features:
- Se a percentagem de missing values for maior que um dado threshold
- Dependendo do nível de correlação entre a variável e o target (usar teste do qui-quadrado)
- Caso tenha um baixo desvio padrão (quase constante)
- Caso esteja muito correlacionado com outra variável independente, mantendo apenas uma
Podemos, ainda, utilizar técnicas mais sofisticadas, tais como:
- PCA (Principal Component Analysis)
- Utilizando um algoritmo de machine learning para selecionar as features mais importantes
Missing Values Depois de uma análise sobre o número e percentagem de missing values numa determinada feature, podemos optar por tratá-la de uma das seguintes formas:
- Remover a feature totalmente
- Substituir os missing values pela média
- Interpolar o valor dos missing values
Discretization Codificar valores categóricos (ou nominais) em números. Existem vários métodos para isso:
- Label encoding: os inteiros possuem uma relação de ordem natural entre si
- One-hot encoding: não existem uma relação de ordem
Binning Neste caso, vamos agrupar os valores de uma data feature em bins. Pode tornar o modelo mais performante, mas estamos, possivelmente, a sacrificar informação.
Feature Engineering Simplesmente extrair features a partir de outras.
A partir de uma data de criação (2021-10-29 16h30), podemos retirar diversas outras features:
- Ano, mês e dia
- Dia da semana
- Hora e minutos
- É fim-de-semana? (Sim ou não)
- É feriado?