Tópicos
Porquê Sistemas Distribuídos?
- Modularidade: decoupling de diferentes serviços (separation of concerns)
- Performance e Escalabilidade: mais servidores ⇒ mais velocidade
- Disponibilidade: hardware e software falham constantemente
Padrões
Monolítico
Múltiplos componentes (armazenamento, base de dados, servidor aplicacional, etc) no mesmo servidor. Não é um sistema distribuído.
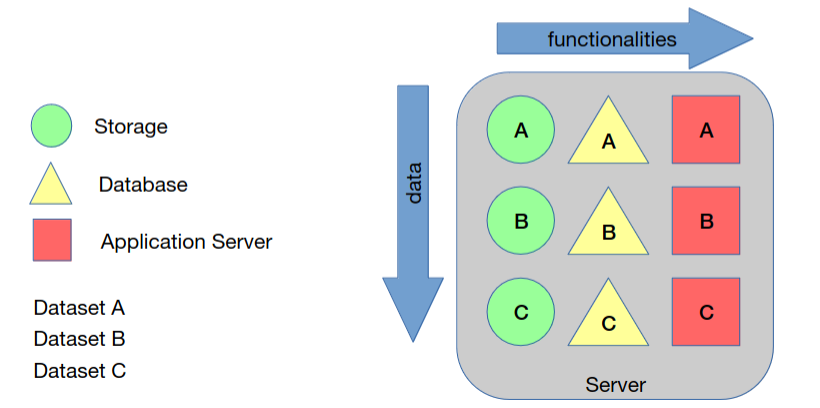
Desafios associados
- E se o servidor não conseguir aguentar com a carga imposta pelos clientes
- Solução: escalar verticalmente (aumentar os recursos computacionais) ou horizontalmente (aumentar o número de servidores); scale-up e scale-out
- E se o servidor falhar?
- Solução: ter redundância ao nível do servidor (réplicas)
Replicação
A partir de agora, estamos a falar de padrões realmente distribuídos.
Neste caso, temos múltiplas cópias da mesma informação ou funcionalidade (redundância). Resolve o problema da disponibilidade, visto que se a réplica 1 falhar, temos a réplica 2. Resolve também o problema da performance e escalabilidade, visto que os pedidos por parte dos clientes podem ser balanceados (load balancing) entre as réplicas.
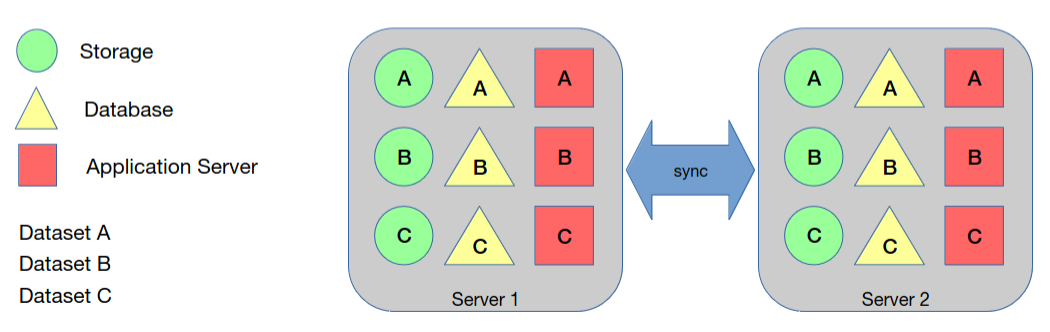
O mecanismo de sincronização pode ser de dois tipos
- Master-slave: onde existe um mestre que recebe as atualizações e os escravos são apenas cópias
- Multi-master: onde todos recebem atualizações e, periodicamente, se sincronizam entre si
Particionamento
Os componentes (ou simplesmente um dos componentes) são divididos horizontalmente (sharding).
Resolve o problema da performance e escalabilidade, uma vez que os pedidos por parte dos clientes são atendidos por um shard específico.
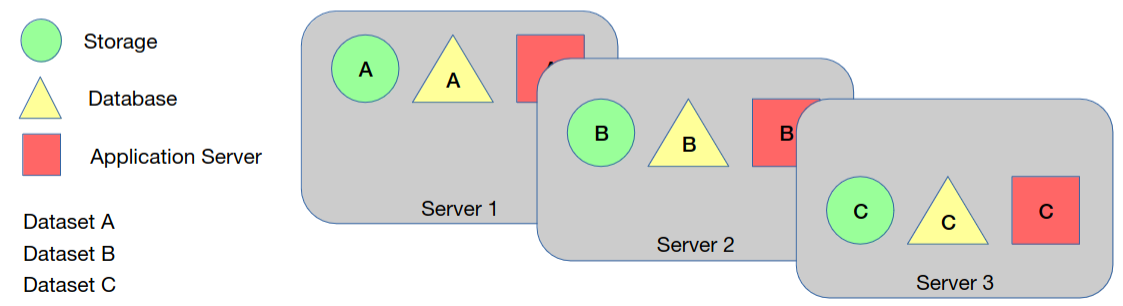
Diferença entre replicação e particionamento
Replicação foca-se em duplicar os dados em múltiplos servidores. Particionamento foca-se em dividir os dados em partes menores distribuídos entre múltiplos servidores.
Service-Oriented
Os componentes são divididos verticalmente (microsserviços).
Resolve o problema da modularidade e da escalabilidade, já que cada servidor pode ser responsável por papéis diferentes. Um para manusear armazenamento, outro para manusear bases de dados, outro para manusear serviços aplicacionais, etc.
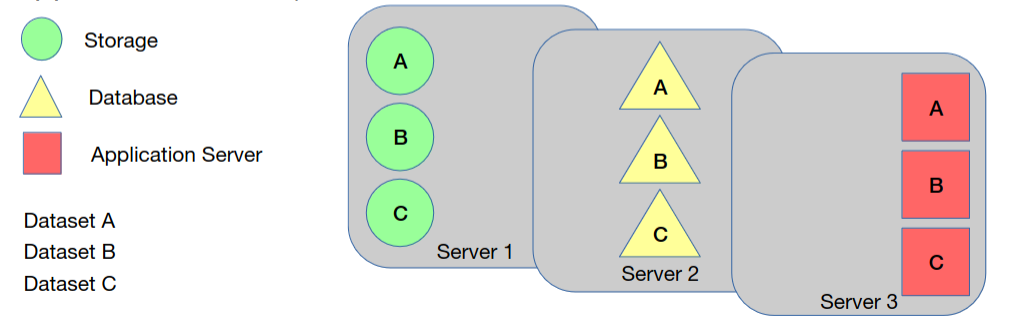
Pontos fracos de arquiteturas baseadas em microsserviços
- Consistência: atingir consistência entre todos os serviços é muito complicado; ou requer a utilização de protocolos avançados de consensus ou simplesmente assume-se que inevitavelmente a consistência irá acontecer (consultar https://en.wikipedia.org/wiki/Eventual_consistency)
- Deployment: por se tratarem de muitos serviços, este passo torna-se mais complicado do que em outros cenários; o mesmo vale para a testagem do software
Arquiteturas
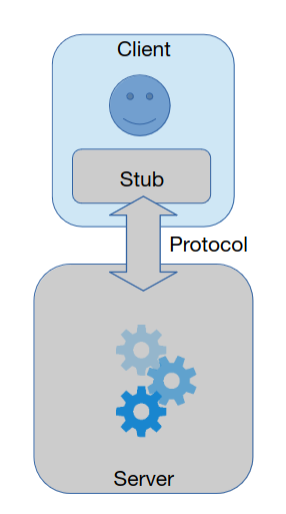
Cliente-servidor
Funcionalidade e informação estão no servidor. Cliente corre uma stub, que providencia uma API para interagir com o servidor; abstraindo os detalhes do protocolo.
Exemplo: servidor web, cujo protocolo é HTTP
Uma vez que existe apenas um servidor, não é possível garantir escalabilidade ou disponibilidade.
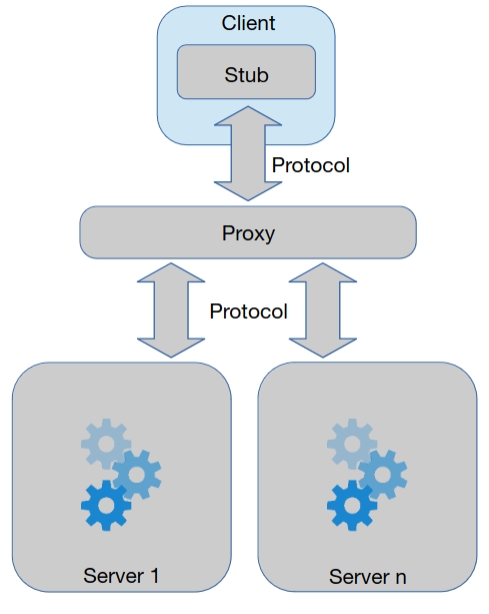
Proxy-server
Existe um proxy que é responsável por abstrair a interação com múltiplos servidores. Esta arquitetura é boa para utilizar com conceitos como: replicação ou sharding.
Um proxy é diferente de um stub no sentido em que o primeiro torna transparente, para os clientes, o conjunto de servidores existente. Por sua vez, o stub, torna transparente, também para os clientes, o protocolo utilizado (imposto) pelo servidor.
Desta vez, apesar de ser possível escalar o número de servidores existentes, o proxy tornou-se um ponto único de contenção (todos os pedidos passam por aqui) e de falha (existe apenas um).
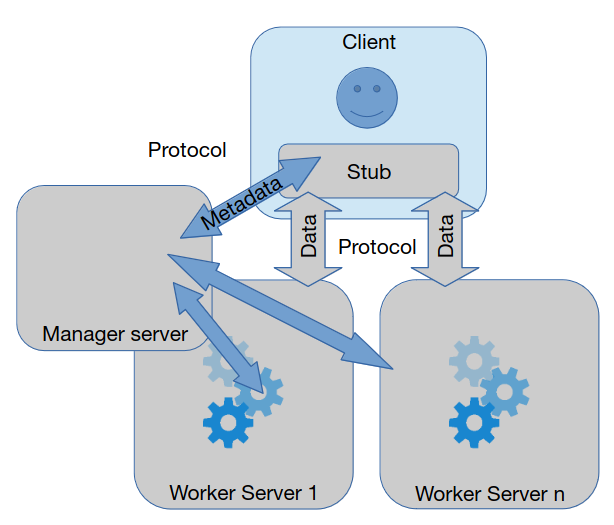
Manager-worker
Funcionalidade é repartida entre um manager e vários workers.
Existem dois tipos, muito parecidos, desta arquitetura
- Manager delega trabalho: neste caso, o manager é responsável por receber a carga de trabalho por parte do cliente, delegá-la para um dos workers (algoritmo de escalonamento), receber a resposta e reencaminhá-la para o cliente
- Manager serve apenas como gestor: desta vez, o manager é apenas responsável por gerir os workers (a sua utilização, etc). Depois de receber informação, por parte do cliente, sobre uma determinada carga de trabalho (metadata) informa, de volta, qual worker o cliente deverá contactar. A partir daí, a comunicação é feita entre o cliente e o worker, verdadeiramente utilizando a carga de trabalho (data)
Tal como no caso do proxy, o manager é um ponto único de contenção e de falha.
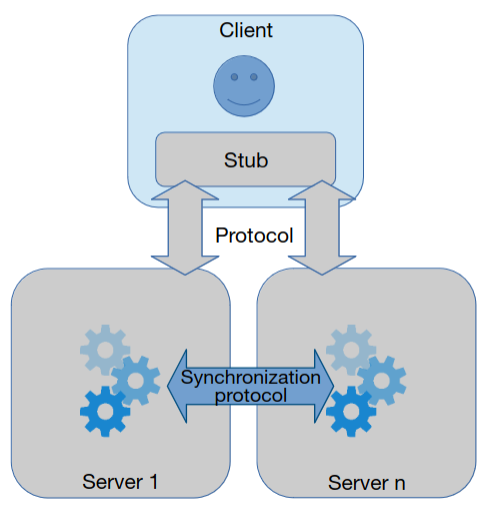
Server group
Existe um grupo de servidores e qualquer um dos servidores pode servir um qualquer cliente. Caso um servidor falhe, o serviço continua no ar por existirem outros. Não existe um único ponto de falha.
É utilizado um protocolo de sincronização para assegurar que existência consistência no estado de todos os servidores (requer coordenação). No entanto, este protocolo tende a ser complicado de implementar e executar, limitando a escalabilidade horizontal.
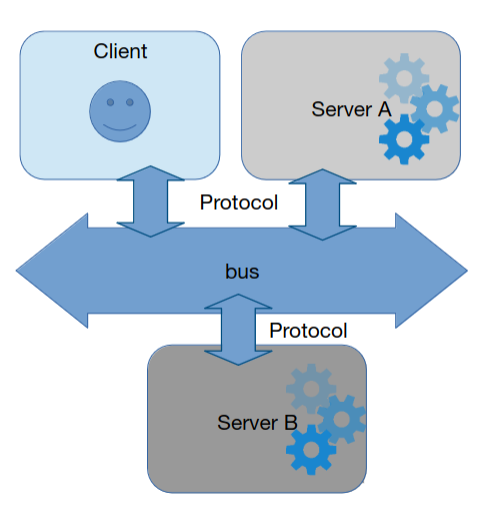
Bus
Arquitetura que faz lembrar um message broker (tipo RabbitMQ).
Participantes publicam e consomem mensagens do bus utilizando um certo protocolo. Neste sentido, existe um decoupling total entre os produtores e os consumidores. Estes, não necessitam de se conhecer. A flexibilidade é muito maior, também, uma vez que um certo cliente (utilizador, servidor, etc) pode tanto consumir como publicar.
A adição de novos clientes ao sistema é muito simples. Bastando, para isso, colocar o cliente a utilizar o bus.
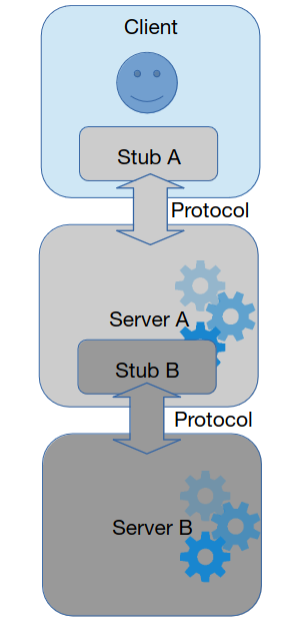
Multi-tier
Também conhecida como arquitetura por camadas. Cada servidor atua como se fosse um cliente para o próximo nível. Uma espécie de aninhamento de padrões cliente-servidor.
Permite um deployment bem mais simples e independente, permitindo uma escalabilidade atómica.
Exemplo: Swap, visto nas aulas
- Protocolo A = Web
- Stub B = Database Driver
- Protocolo B = SQL
O estado, em sistemas multi-tier, é, normalmente, dividido da seguinte forma
- Não existe estado nos tiers superiores (servidor web)
- Estado inconstante (variáveis) ou cached nos tiers do meio (servidor aplicacional)
- Estado persistente nos tiers inferiores (base de dados)
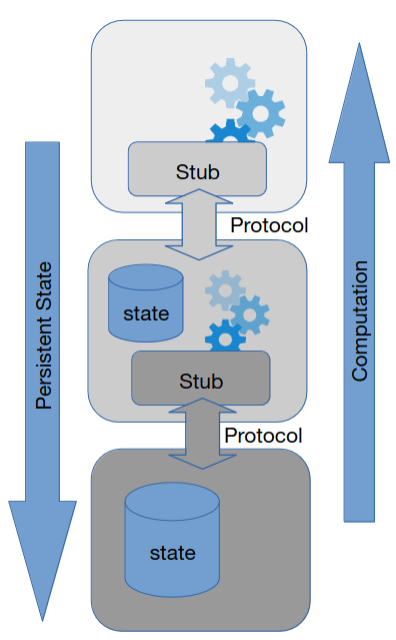
Para assegurar disponibilidade devemo-nos preocupar com todos os tiers ao mesmo tempo. Isto pois, os mesmos dependem diretamente uns dos outros.
Uma vez que a computação é stateless, esta é mais fácil de replicar, já que não necessita de nenhum protocolo de coordenação. No caso de informação persistente, a história é outra e necessitamos de protocolos capazes de criar um consenso geral entre as diferentes réplicas. Além disso, se falarmos de tolerância a falhas, serviços stateless também são mais fáceis de manter e recuperar.